
* Weekly nlp 6에 해당하는 내용
본문 링크: https://jiho-ml.com/weekly-nlp-6/
Week 6 - 박 대리, 얘네 문서들 주제별로 분류해오게
오늘은 박 대리를 도와 문서 분류를 자동으로 처리할 수 있나 document(text) classification에 대해 공부를 해보겠습니다.
jiho-ml.com
Binary Classification
이분법
Linear Regression
- ML에서 가장 간단한 모델
- 여러 개의 (x, y) 데이터가 주어졌을 때, 가장 잘맞는 직선을 찾는 알고리즘
- 보통 y는 scalar, x는 n차원 벡터

하지만 Linear Regressiong은 classification이 아니고 숫자를 예측하는 회귀(regression) 모델임
--> sigmoid(logistic) function을 사용하면 classifcation 모델로 만들 수 있음
Sigmoid Function
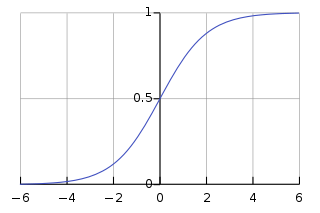
- 0 <= f(x) <= 1, for any x
- 그렇기 때문에 linear regression을 sigmoid와 함께 쓴다면 binary classification 모델로 바꿀 수 있음 --> Logistic Regression Classifier
학습에 어떤 데이터가 필요할까
e.g. 영화 리뷰 긍정(y=1), 부정(y=0) 문장 분류 데이터 --> sentiment analysis (감성 분석)
("정말 재밌게 본 영화. 스토리도 연출도 정말 대박!", 1)
("배우들이 연기를 너무 잘하는데? 두 번 봐도 좋음.", 1)
("올해 최고의 작품!", 1)
("나는 그냥 별로. 졸다가 나왔다.", 0)
("도대체 이 뻔한 스토리는...", 0)
("정말 돈 아깝다. 인생 최악의 영화.", 0)- x = 숫자가 아니고 문자열(string)임
- logistic regression 모델은 x가 n차원의 벡터여야 학습시킬 수 있음

- string을 벡터로 만드는 것 --> vectorization
- tf-idf BoW vector로 vectorize
- linear/logistic reg에서는 각 column이 하나의 feature로 취급 됨
- 만약 vocabulary가 5000개인 corpus가 있다면 --> 각 문장 = 5000 x 1 column vector
- logistic reg는 5000차원의 x를 주어진 y value들에 잘 맞는 직선을 찾는 학습 과정을 거침
- 학습 후, 새로운 문장들(= 검증 셋 = evaluation set)이 주어졌을 때는 logistic reg는 다음과 같은 결과를 줌
("배우 연기 대박! 진짜 좋다", 0.95)
("최고다 최고. 스토리 작품성 모두", 0.85)
("괜찮았어. 재미는 있었거든", 0.63)
("최악의 작품", 0.05)
("왜내가 이 시간을 아깝게..", 0.1)
("아쉽다 뭔가. 2% 부족한 영화", 0.4)- 이 숫자들은 전부 0~1 사이 --> 점수/확률 둘 중 아무거나로 생각하면 됨
- probability score라고 불림
- 0에 가까울수록 부정, 1에 가까울수록 긍정 평가
- threshold = 0.5로 결정하고 정확도 계산하면 됨
Feature Importance
- 모델이 가장 중요하게 보는 단어(feature)들을 알아보는 것
- 주로 predicted y 값을 계산할 때 x에서 각 row들에게 어떤 weight을 계산한 것을 보면 됨
- 예를 들어 부정에는 negative weight, 긍정에는 positive weight
- feature importance graph를 그려보면 모델이 무엇을 학습했는지 이해하는데 도움이 됨
